DNA saturation mutagenesis: Identifying which mutations really cause disease
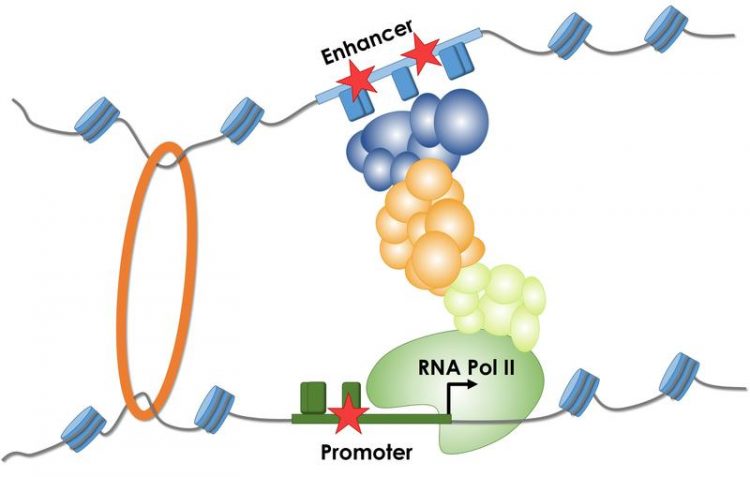
The figure shows the process of gene transcription by RNA Polymerase II and the importance of regulatory sequences (promoter and enhancer). Mutations (stars) impair or increase the binding of differen © Martin Kircher
Many diseases occur because a person’s DNA contains errors, so-called mutations. These cause vital protein molecules to be produced incorrectly. Sometimes the molecules are altered to such an extent that they are no longer able to perform their function.
But more often, modifications in the gene control regions (regulatory sequences, also known as promoters and enhancers) cause the wrong amount of protein to be produced. The cells produce either too much or too little protein, or none at all.
“That can, for example, result in cancer if a type of protein that promotes cell division is produced in too great a quantity,” explains Martin Kircher, head of the BIH Junior Research Group on Computational Genome Biology and lead author of the paper.
Yet cancer cells are precisely where many mutations often occur – and some of these mutations have no impact while others actually cause or speed up the disease by influencing how much protein is produced. Before physicians prescribe a therapy that specifically combats certain mutations, they should know what role these play for the disease.
To help with this, a team of scientists around Dr Kircher took the control regions of 20 disease-relevant genes and modified them piece by piece – or to be more precise, the DNA base by base. For this purpose they developed a method that was able to perform these modifications in a high-throughput manner and allowed them to test them simultaneously. Using cell cultures, they examined what impact each modification had on protein production.
“Some 85 percent of modifications have no measurable effect, while two-thirds of the remaining 15 percent reduce the amount of protein produced,” reports Dr Kircher. And the extent to which they effect cell activity is heavily dependent on the individual mutation and the control region investigated: “Replacing a base with another one usually has less impact than completely removing the base.”
The control elements investigated were from genes that are modified in patients suffering from cancer, heart failure, genetically high cholesterol, or various rare diseases. The researchers have made the results of their mutation analyses – more than 30,000 in total – freely available to anyone on the internet. Martin Kircher now hopes that this treasure trove of data will be used:
“It would be great if physicians who have analyzed their patients’ DNA would consult our database to find out what effect the identified mutation, in all likelihood, has. This will enable them to assess whether the modification found in patients is suitable for a targeted therapy.”
The considerable time and effort needed to test 20 of possibly hundreds of thousands of control regions raises the question of whether machine learning or artificial intelligence could help predict which mutations produce which effects. There are already various computer programs that are trying to do exactly that.
Dr Kircher and his colleagues therefore also studied how well different programs could predict the modifications observed in the cell culture. “The results were unfortunately very disappointing,” reports the Bioinformatician, “because the predictions rarely corresponded with our observations. Sometimes they even predicted the exact opposite.” The scientists now hope that their comprehensive data set can also be used to improve such predictive software.
doi: 10.1038/s41467-019-11526-w. PMID: 31395865
https://www.bihealth.org/en/notices/press-release-dna-saturation-mutagenesis-ide…
Media Contact
All latest news from the category: Life Sciences and Chemistry
Articles and reports from the Life Sciences and chemistry area deal with applied and basic research into modern biology, chemistry and human medicine.
Valuable information can be found on a range of life sciences fields including bacteriology, biochemistry, bionics, bioinformatics, biophysics, biotechnology, genetics, geobotany, human biology, marine biology, microbiology, molecular biology, cellular biology, zoology, bioinorganic chemistry, microchemistry and environmental chemistry.




Newest articles

First-of-its-kind study uses remote sensing to monitor plastic debris in rivers and lakes
Remote sensing creates a cost-effective solution to monitoring plastic pollution. A first-of-its-kind study from researchers at the University of Minnesota Twin Cities shows how remote sensing can help monitor and…

Laser-based artificial neuron mimics nerve cell functions at lightning speed
With a processing speed a billion times faster than nature, chip-based laser neuron could help advance AI tasks such as pattern recognition and sequence prediction. Researchers have developed a laser-based…

Optimising the processing of plastic waste
Just one look in the yellow bin reveals a colourful jumble of different types of plastic. However, the purer and more uniform plastic waste is, the easier it is to…