Unpacking pecking orders to get the gist of web gab
The ISI study characterized online posts according a schema of speech acts. While some speech-act characterization was done by hand in this study to test the results, the ISI group has already developed effective software to accomplish the task automatically. Credit: USC Information Sciences Institute
A USC Information Sciences Institute system pulls answers from online conversations by identifying the alpha chatterers.
The system, to be presented at a conference on human language technology on June 6, was developed to analyze technical conversations in which an objectively correct answer exists. But the method for statistically characterizing response by the group to individuals is generalizable.
Online communities are now firmly established in domains ranging from high school gossip to professional open-source software design discussions, generating huge repositories of records of human knowledge processing, pre-converted to digital form.
“For study of online natural language interaction, it’s the mother lode,” says Eduard Hovy of the University of Southern California Information Sciences Institute.
Such sites provide raw material for a new method that may, among other things, enable Internet chat room users to get a statistical measurement of their influence in their room.
This research is one of the first quantitative studies in the field of natural language processing that takes account of the fact that chat conversations are structured interactions among a large number of people.
In the long term, research in this area will lead to the development of systems that can automatically produce reports and summaries of meetings, researchers hope.
It’s easy to simply harvest factoids from text, said Hovy (left), who holds an appointment as research associate professor in the USC Viterbi School of Engineering department of computer science in addition to his post as deputy director of the ISI Intelligent Systems Division and director of the ISI Natural Language Group.
But the fact that human conversation has an inherent structure, including temporal ordering, references to previous statements, labeled sourcing and other clues opens the door to much deeper machine-generated understanding.
To make use of the structure, the team used a graph-based algorithm called HITS (Hypertext Induced Topic Selection) originally used by Cornell computer scientist Joel Kleinberg to rank and classify web pages by their connections to each other.
In the study, connections between conversation participants replace the web links for the HITS analysis.
The interactions used in the study were threaded discussions from three semesters of a USC undergraduate course in computer science, including 2214 messages in 640 threads, all discussing class material and posing questions about problems.
The goal was to extract from the conversation the best answer to the questions discussed. And, according to the paper, the system works — not perfectly, but much better than one that selects answers at random. Random selection got the answer (as determined by human inspection) right 87 out of 314 times, where the best implementation of the HITS system was correct 221 times.
The ISI implementation of HITS integrates three separate elements–speech act analysis, lexical similarity, and poster trustworthiness–to create links for interpretation for individual conversation participants.
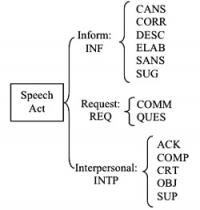
Speech act analysis classifies the statements in the record according to what they do in the context of the discussion, assigning each to one of thirteen kinds of acts, grouped in three categories: inform, request, social-interaction.
The “inform” speech act category includes corrections, descriptions, elaborations, suggestions, and answers to questions, both simple and complex. “Requests” include not just requests for information but also for action, namely commands. “Social” speech acts include acknowledgements, thanks, compliments, criticisms, objections, and supportive statements.
Lexical analysis looks for similarities in the vocabulary of responses to see which are related to each other. From this the system can determine the threads of the conversation, and decide when new subtopics are split off.
Finally, poster trustworthiness measures the degree to which participants accept statements made by each individual. This is determined by scoring responses to a given person’s posts as either negative or positive. Over time, people whose statements are more positively viewed become more central and more trusted in the online community.
To test the method, part of the data (the classification of the speech acts) was initially human coded. After it was trained, the machine system was then applied to the same data, and its performance was compared to that of the human coder. It achieved accuracy of between 65% and 70% — a figure that is likely to improve.
How soon will it be possible to download a version that can score a given poster’s influence in his/her chat community? “This technology has considerable potential for commercialization,” said Hovy.
Media Contact
More Information:
http://www.usc.eduAll latest news from the category: Information Technology
Here you can find a summary of innovations in the fields of information and data processing and up-to-date developments on IT equipment and hardware.
This area covers topics such as IT services, IT architectures, IT management and telecommunications.




Newest articles

Magnetic tornado is stirring up the haze at Jupiter’s poles
Unusual magnetically driven vortices may be generating Earth-size concentrations of hydrocarbon haze. While Jupiter’s Great Red Spot has been a constant feature of the planet for centuries, University of California,…

Cause of common cancer immunotherapy side effect s
New insights into how checkpoint inhibitors affect the immune system could improve cancer treatment. A multinational collaboration co-led by the Garvan Institute of Medical Research has uncovered a potential explanation…

New tool makes quick health, environmental monitoring possible
University of Wisconsin–Madison biochemists have developed a new, efficient method that may give first responders, environmental monitoring groups, or even you, the ability to quickly detect harmful and health-relevant substances…